Setting Up Our Database
After a semester of tussling, the database API is finally functional! Our analysts can now query price and fundamental data using our custom API, with optional filters for date, ticker, and attributes.
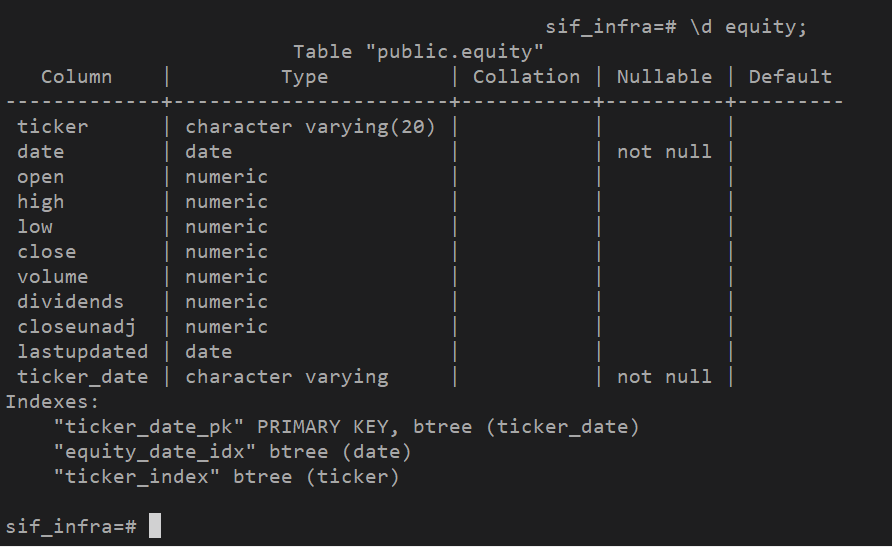
We use a Postgres database to store our fundamental and price data, and interact with it using Psycopg2, a Python library. We use Psycopg2 to directly connect to the Postgres database hosted on a DigitalOcean droplet. Our API is written in Python; and contains custom functions that take in parameters passed by the user, forms a SQL query for execution by Psycopg2, and parses the output into a dictionary of Pandas dataframes.
Our API went through a few changes; at the start, we had an additional backend server to process calls from the frontend, but later changed to directly connect to the database with Psycopg2. One of the main issues with the database at the start was its speed, which we were able to drastically improve by indexing the database on the date and ticker fields.
In addition to querying the database, our API also has various data utility tools like writing to the database, creating a universe screener, and converting the format of fundamental data to usable formats. We obviously, ran into many challenges while creating these tools. For example, writing a universe screener was trickier than expected, since we needed to account for lookahead bias, missing data, and different reporting dates of market capitalization. Our solution was to create standardized cutoff dates per quarter, and to only use data reported before the cutoffs.
Our analysts have been using our API in conjunction with our custom research framework, which implements common transformations, backtesting, and basic performance metrics.
Going forward, we are planning on adding support for automatic updating with new data, and adding alternative data such as ETFs and volatility.