Alternative Data Sources
Introduction
The idea for this project is to create a data pipeline for alternative data sources. As we currently don’t have much non-traditional data based research, having viable sources of alternative data allows for interesting and new quantitative finance research. One of the main issues with current alternative data sources is that it exists as a large static dataset. While this allows us to research it heavily and build a model out of it, the lack of live data poses a struggle for us to deploy the model in a live setting, as we wouldn’t be able to adjust to changing market conditions.
Project Description
This project consisted of multiple steps to create viable alternative data pipelines, these being: brainstorming usable data sources, identifying if these sources can be accessed, and building data scripts to access these.
Brainstorming Data Sources
The first stage of this project was to brainstorm a big list of potential alternative data sources. These ideas had to be unique in that it could provide interesting analysis, while at the same time have some sort of underlying correlation to finance securities. One source of inspiration was to go onto a major alternative data site like https://www.quiverquant.com/, and get ideas from the data sources they provide. It also allows you to see what areas they don’t capitalize on (international data for example), and seek out data sources related to that.
Validating Data Sources
Once we’ve compiled a decent list of potential data sources, the next step is to validate which sources are possible to collect, and which aren’t. The problem with a lot of these data sources is that unless it’s provided for free by the Federal Government, it’s usually either impractically difficult to collect, or primarily behind paid barriers. This led to cutting out several data sources after realizing it’s impractical to try and build scripts for these.
Data Sources
US Senators/Representatives Stock Disclosures
This scraper gets all the most recent senate/representative stock disclosures. Whenever a US politician at the federal level purchases any stock, they’re required to disclose it to the government within 30 days regarding what stock they purchased, and how much of it. This allows us to analyze their trades and see if any internal information was used to make those trades, and if that’s something we can capitalize on. Pairing this with some source on what committees different members are on could be interesting.

Canada/UK Government Contracts
This scraper gets all the most recent government contracts that were posted by the Canadian and uk governments. The data we’re able to obtain from this are the values of the different contracts, what economic sector they apply to, more specifics about the contract, if it’s recurring, etc. Using this continuous scraper, we can store and track what companies are generally winning more contracts with the government, as well as what economic sectors are getting more contracts overall as a trend.

News Data
This data has two parts. The first being scraping the live news RSS feeds, and using NLP to gain insight from it. We can identify what topics are trending/being covered recently, and if that pertains to certain sectors or companies. We can also look at the sentiment of these articles and see if they reflect any new information. A potential idea is to create a strategy that trades based on similar articles from different news companies being posted at the same time.
The second part of this is being able to search a topic, and find relevant news articles about it that were recently posted. We can use this to research new ideas and see if there is a generally positive or negative consensus about or, and how the current market is reacting to a specific topic.

Congress Bills
This data source shows all the current congressional bills. It shows what bills are currently introduced, being processed, passed, etc., and more specific information about each bill. It could be a potentially viable data source by looking at what bills each congressman is supporting, and whether it is due to lobbying influence, insider information, etc.

Reddit Posts
This data source allows us to collect data from posts made on reddit. This data includes the post heading, the text in the post, the response to it, etc. We’re also able to search within subreddits to find the top/hot/new/controversial posts. This data source could potentially be useful to see how grassroots support/disapproval is towards a certain topic, and whether it is trending or not. Could be relevant for some potential trading strategy.
SEC Edgar Database
This data source took the longest to parse through, but was definitely the most rewarding. It allows us to view company financial reports/disclosures, within 1-2 days after a certain event occurs. Using this and effective NLP, we can analyze corporate finance data and see if they’re going to beat targets or not.
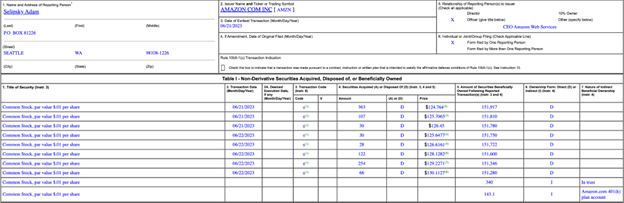
Another useful piece of information found in this data source is director/c-suite employee financial disclosures. When a person is at a certain “rank” within a company, they need to disclose to the SEC whenever they buy or sell their own company’s stock, within 2 days of it happening. This is a gold mine of data, and we can use this information to deduct if a person is trading their stock based on insider information. There are between 2k-10k trading disclosures each day from executives, which is a ton of useful data that we can look through.
Future Data Sources
This is a collection of sources I’ve written down to look at, but haven’t gotten around to do so.
US Government Contracts
Same thing as the Canada/UK one, but this time involving US government contract postings. The government has a certain API they use to make this information public and easily accessible, so that’s something to look at.
UK and Canada Stock Purchase Disclosures
Being able to look at the stock disclosures of politicians within the UK and Canada. This data source is still in the “check if viable” stage as it’s not confirmed if this is public, but if we’re able to find a way to extract it, a script for it will be created.
Company Lobbying Data
Allows us to view what politicians are getting lobbied, and what companies are spending the most to do that. We can also potentially view what economic sector/policy these companies are trying to get passed through lobbying, and make trades based on that.
Patent Filings
Let us view which companies are doing the best in regards to gaining new technologies, which allows us to see which companies are best positioned into the future. This means that we can start making longer-position trades within these companies, with the expectation that they will outperform targets with the new technologies they’ve patented.
Final Takeaways
Ultimately, I was able to achieve what I had envisioned at the start of this project, finding a bunch of useful alternative data sources that could be used to create strategies. With the list of future data sources that can be explored later, this project sets a good foundation for future alternative data sources to be explored.